Semantic Match Deep Dive 2
Introduction
Last post, we already talked about the basic concepts of s2s&s2p tasks. Now I have done some experiments on compared the different methods to verify the effectiveness.
The experiments only test the effectiveness of the inference models without any finetuning
Dataset
Here I used two types of dataset, one is classificaiton dataset, and another is passage retrieval dataset. The details information as follows.
| Name | Task | Size | Link |
|---|---|---|---|
| toutiao-text-classification-dataset | classification | 7k | https://github.com/aceimnorstuvwxz/toutiao-text-classfication-dataset/tree/master |
| DuReaderretrieval | passage retrieval | q:5k, p:4w | https://www.luge.ai/#/luge/dataDetail?id=55 |
Results
Results of s2s only retrieval
Here I used BGE M3 model to do the cosine similarity match, the results is below.
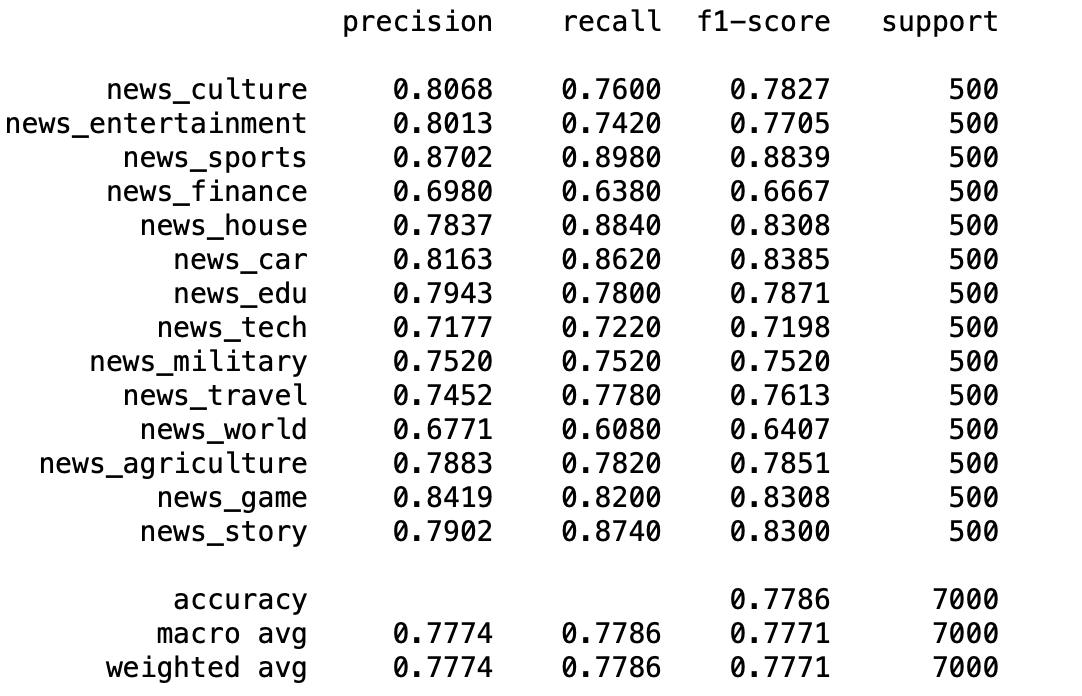
Results of s2s retrieval(top 5)&rerank
Then I added second stage rerank with retrieval top 5 candidates, the results as follows.
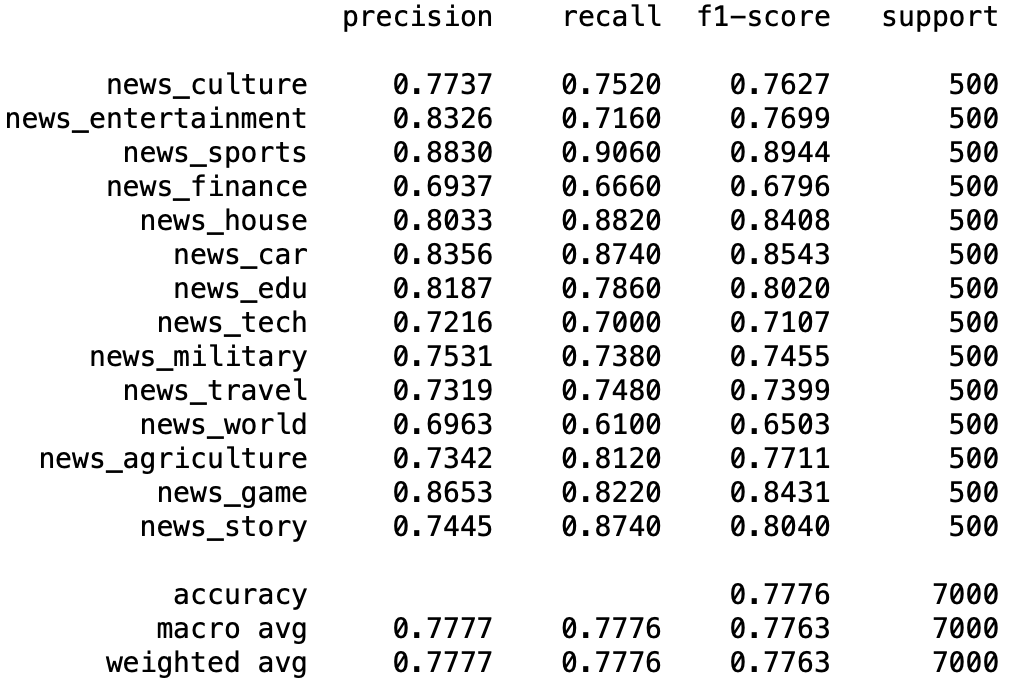
Results of s2s retrieval(top 100)&rerank
I also tried retrieval top 100 candidates and do reranking, the results as follows.
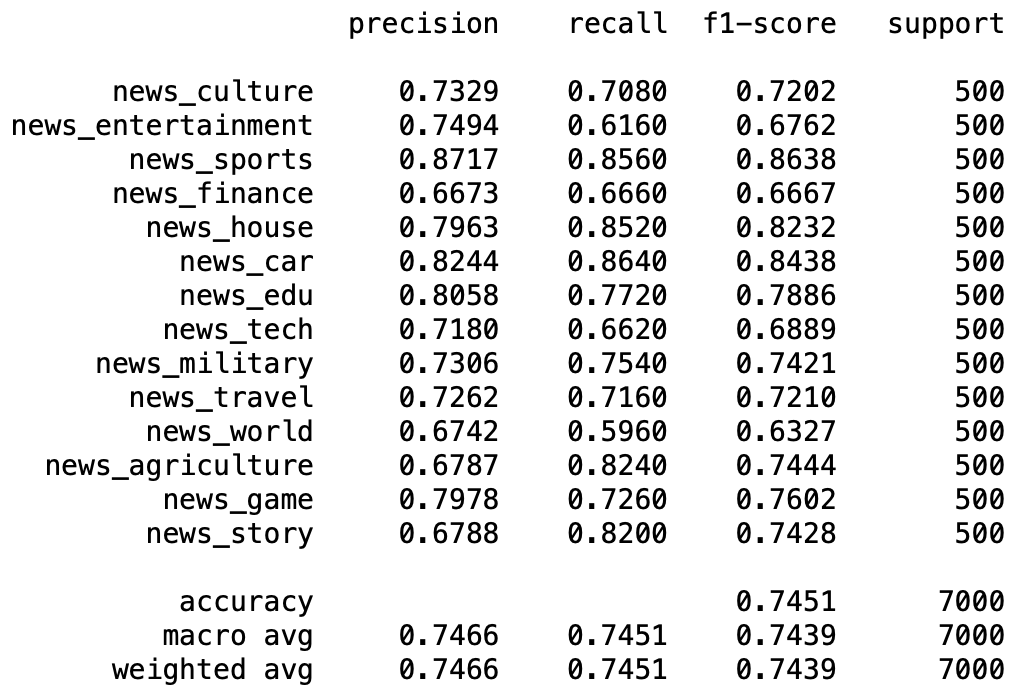
Results of s2p
| Method | top1 | top3 | top5 | top10 |
|---|---|---|---|---|
| retrieval-only | 0.3309 | 0.5967 | 0.7151 | 0.8386 |
| retrieval-5 + rerank | 0.4064 | 0.6530 | 0.7151 | \ |
| retrieval-20 + rerank | 0.4266 | 0.7245 | 0.8280 | 0.8992 |
The table shows after reranking, the retrieval accuracy improved significantly, top 1 accuracy increased 7% after reranking top 5 retrieval results, top3 accuracy increased from 59.67% to 72.45% by reranked top 20.
However, rerank is really consuming, so in the reality it’s not a effective way to do reranking or we use less retrieved results to do reranking.