Semantic Match Deep Dive 1
Introduction of Semantic Match
Semantic match is one of the basic tasks of NLP, the goal of the task is to determine whether two sentences have the same semantic meaning. Semantic match is widely used in natural language processing, such as question answering, information retrieval, machine reading comprehension, etc.
Semantic match tasks can be divided into two categories:
- sentence to sentence(S2S)
- sentence to passage(S2P)
sentence to sentence(S2S)
The goal of sentence to sentence is to determine whether two sentences have the same semantic meaning. S2S tasks are widely used in intent recogniton in question answering system, such as Ecommerce, Finance, Medical etc. This task is semantic matching of short texts, such as “How much does it cost to buy a house?” and “How much does it cost to buy a house?”, so this type is relatively easier.
sentence to passage(S2P)
The sentence to passage is to determine whether there is a semantic relationship between two sentences and the passage. Due to the bias in the length of sentences, there will be a certain degree of bias in short sentences in projection space.
Semantic Match Models
There are two common semantic matching models, one is a representation-based semantic matching model, and the other is an interaction-based semantic matching model.
Represtation-based model
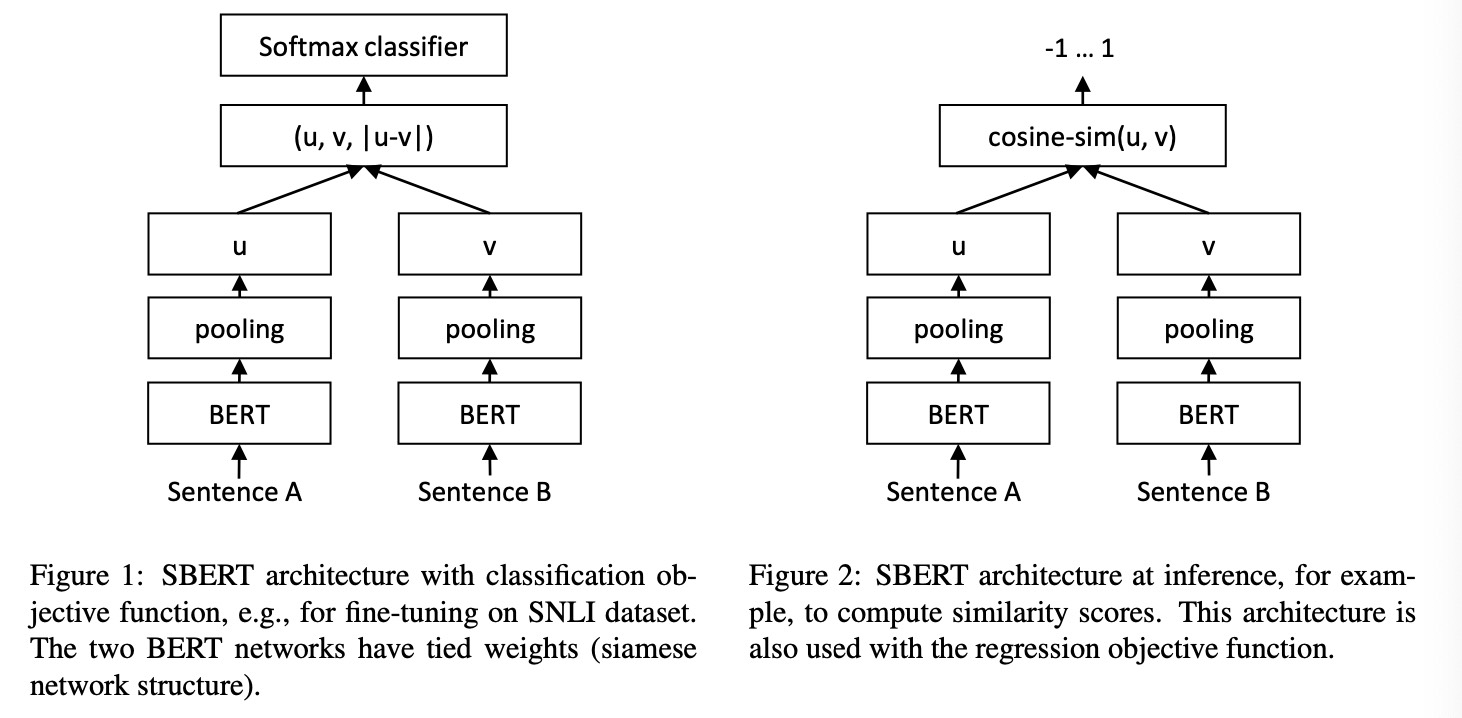 The representation-based semantic matching model is represented by the two-tower model of Sentence-Bert1. The left side is training process, the sentence first output by Bert, and then pooling to get the vector u, v, and then concatenate u, v, |u-v|, |u-v| is then multiply by a trainable weight to get final result through softmax. The right side is the inference process, use the model to get the vector of A(u) and B(v), and then get the cosine similarity and filtered by certain threshold.
The representation-based semantic matching model is represented by the two-tower model of Sentence-Bert1. The left side is training process, the sentence first output by Bert, and then pooling to get the vector u, v, and then concatenate u, v, |u-v|, |u-v| is then multiply by a trainable weight to get final result through softmax. The right side is the inference process, use the model to get the vector of A(u) and B(v), and then get the cosine similarity and filtered by certain threshold.
There are two implementaion of Sentence Bert, Bi-encoder and Dual-encoder respectively.
- Bi-encoder: Compute the query and candidate vector representations with shared transformer encoder, and then compute the cosine similarity between the query and candidate vectors, to determine the similarity of the query and candidate. The typical Bert-like model is M3E, text2vec, BGE.
- Dual-encoder: Compute the query and candidate vector representations with different transformer encoder.
The two encoders in the Dual-encoder model have independent parameter spaces and state spaces, the Dual-encoder model can process and extract the features of Query and Candidate more flexibly. The training and inference costs of Dual-encoder models are usually higher than Bi-encoder models.
Interaction-based model
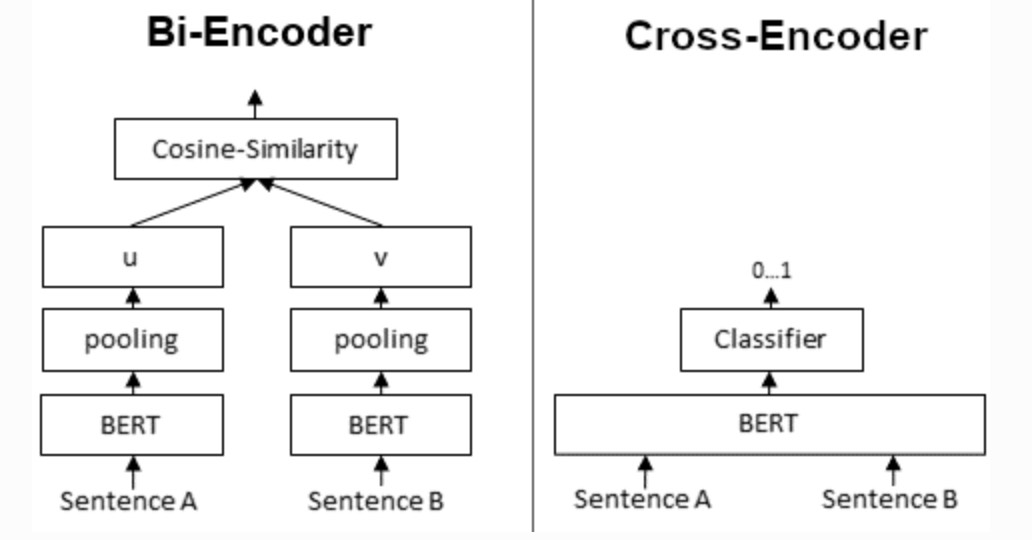 The interactive matching scheme is as shown on the right, which splices two pieces of text together as a single text for classification. Interactive matching allows two texts to be fully compared, so it performs much better, but it is inefficient in retrieval scenarios due to the on-site inference of vectors is required, and representation-based method can calculate and cache all Candidates in advance. During the retrieval process, only vector for Query is computed, and then all Candidates are calculate the similarity. However, relatively speaking, the degree of interaction of characteristic formulas is Shallow and generally less effective than interactive.
The interactive matching scheme is as shown on the right, which splices two pieces of text together as a single text for classification. Interactive matching allows two texts to be fully compared, so it performs much better, but it is inefficient in retrieval scenarios due to the on-site inference of vectors is required, and representation-based method can calculate and cache all Candidates in advance. During the retrieval process, only vector for Query is computed, and then all Candidates are calculate the similarity. However, relatively speaking, the degree of interaction of characteristic formulas is Shallow and generally less effective than interactive.
Multi-stage Retrieval
The more common way is to use the representation-based method to retrieve top-n sentences, and then use interaction-base method match the Query and top-n sentences to get the final ranking results.
- retrieval stage: calcuate the cos similarity between Query and all sentence, and pick the top-n sentences as candidates.
- ranking stage: concat the Query and top-n sentences as a single text respectively, and use Cross Encoder to get the score of the text.
Recommend thesis
- Dense Passage Retrieval for Open-Domain Question Answering2
- RocketQA: An Optimized Training Approach to Dense Passage Retrieval for Open-Domain Question Answering3
- Unsupervised Corpus Aware Language Model Pre-training for Dense Passage Retrieval4
- HLATR: Enhance Multi-stage Text Retrieval with Hybrid List Aware Transformer Reranking5
Dense Passage Retrieval
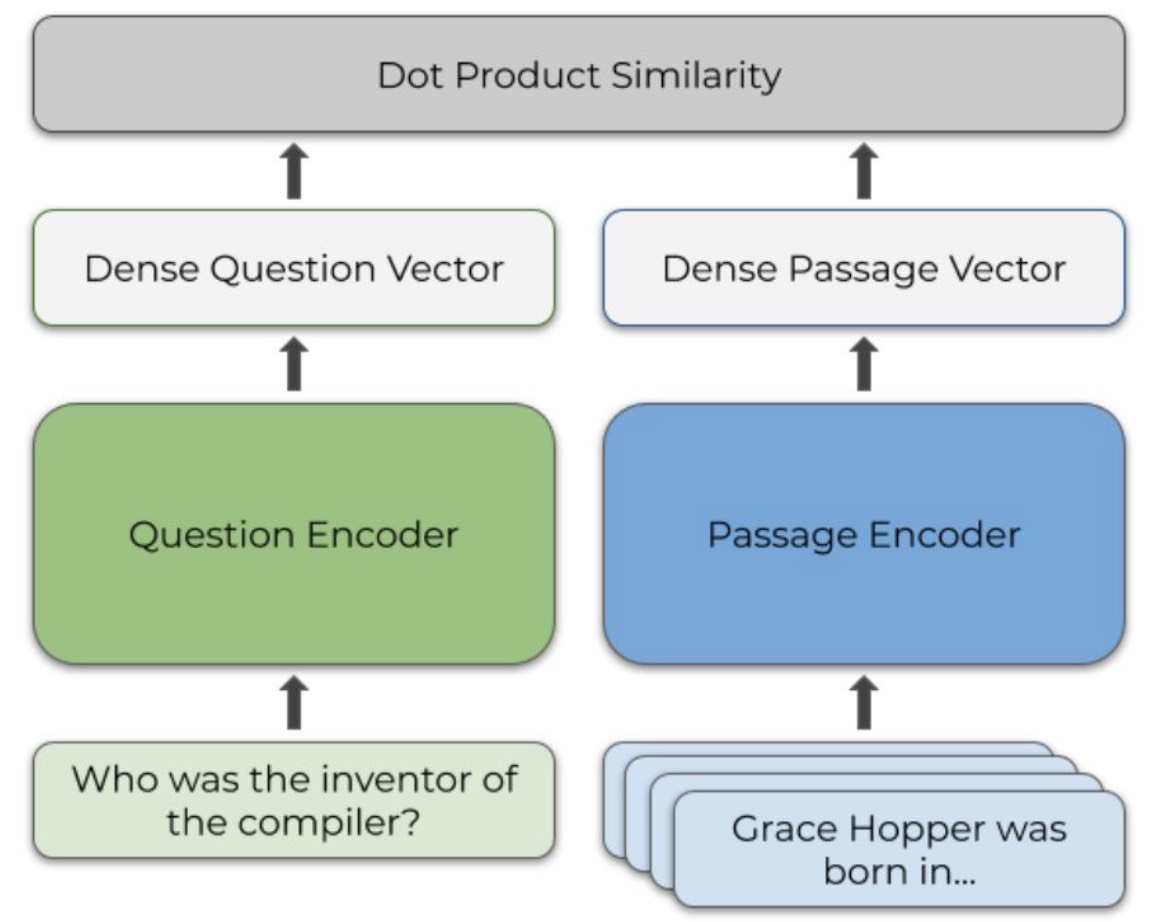 Dense Passage Retrieval,use dual-encoder encode query and passages respectively,and compute similarity then update the model’s weight. The loss is negative log likelihood as following.
Dense Passage Retrieval,use dual-encoder encode query and passages respectively,and compute similarity then update the model’s weight. The loss is negative log likelihood as following.
The proposed three way to generate negatives:
- random pick
- BM25 to pick top-k,remove the origin answer
- in-batch negatives, batch_size=64,then there is 63 negatvies,except the query’s positive, all can be negative.
RocketQA
In the field of dense passage retrieval, there exists a difference between training and inference. In training, only a subset of samples is selected as negative examples, while during inference, all samples are compared. Additionally, during training, there are often a large number of false negative samples, which can be used as positive samples.
To alleivate these two problems, the author has proposed three optimization strategies: Cross-batch negatives, Denoised Hard Negatives, Data Augmentation.
-
Cross-batch negatives firstly compute the embeddings of n samples in m GPUs separately, and then diliver to each GPU. Thus, each training sample has m*n-1 negative samples, which is much larger than the in-batch negatives.
-
Denoised Hard Negatives trains a dual encoder to retrieval negatives, and then train a cross encoder to remove false negatives. In this way, the negatives could be right possible, which is a good way to do data cleaning.
-
Data Augmentation uses the cross encoder to label the unlabeled data, which is a semi-supervised learning method, to enlarge the data scale.
This approach performs advanced on evaluation datasets, but it places high demands on computational resources. For instance, the Cross-batch negatives requires a large number of GPUs. The subsequent training of the dual encoder of the dual encoder also involves a multi-stage process, in curring relatively higher training costs.
coCondense
Condenser is a new pre-training architecture that compresses information into dense vectors through LM pre-training. Most importantly, the authors further propose coCondenser, which adds an unsupervised corpus-level constrastive loss to pre-train paragraph embeddings. It demonstrates performance comparable to RocketQA, the state-of-the-art, carefully designed system. coCondense employs simple small-batch fine-tuning and unsupervised learning, where text snippets are randomly sampled from a document and the model is trained. The objective is to make the embeddings of the CLS token from the same document as similar as possible, while those from different documents should be as dissimilar as possible.
HLATR
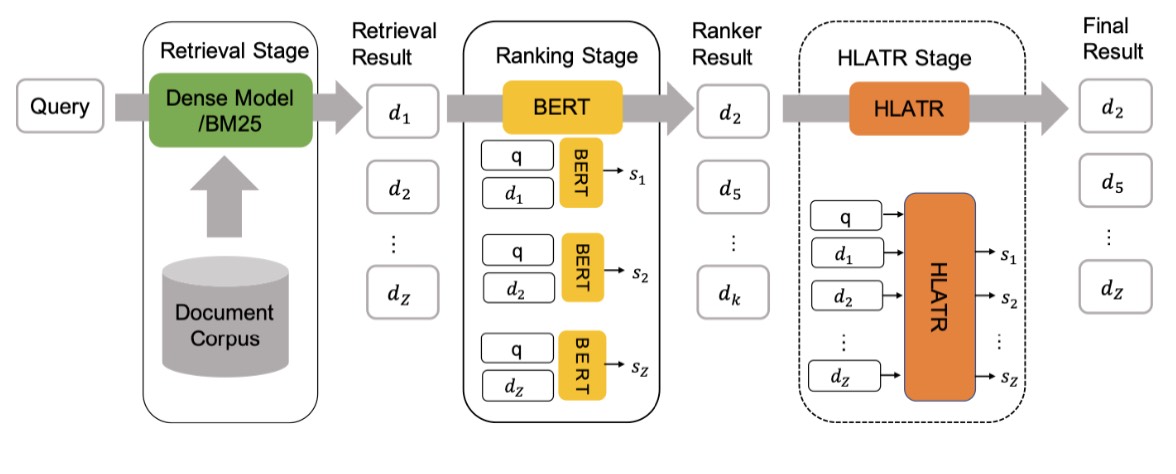 First retrieval and then rerank is a common way to do document retrieval, where the focus is often on optimizing individual models in each stage to improve overall retrieval performance. However, there hasn’t been much in-depth research on directly coupling multiple stages together for optimization. The authors propose a lightweight HLATR framework that enables efficient retrieval and validate it on two large datasets. Here, the authors mention that although both models are involved in ranking, they have different focuses. The representation-based model (retriever) leans towards coarse-grained features, while the interaction-based model (interaction) emphasizes the interaction between query and document. Additionally, the authors perform a simple weighted combination, assigning different weights to the recall and ranking stages, which also improves overall recall performance.
First retrieval and then rerank is a common way to do document retrieval, where the focus is often on optimizing individual models in each stage to improve overall retrieval performance. However, there hasn’t been much in-depth research on directly coupling multiple stages together for optimization. The authors propose a lightweight HLATR framework that enables efficient retrieval and validate it on two large datasets. Here, the authors mention that although both models are involved in ranking, they have different focuses. The representation-based model (retriever) leans towards coarse-grained features, while the interaction-based model (interaction) emphasizes the interaction between query and document. Additionally, the authors perform a simple weighted combination, assigning different weights to the recall and ranking stages, which also improves overall recall performance.
References
-
Sentence-Bert:Sentence Embeddings using Siamese BERT-Networks ↩
-
Dense Passage Retrieval for Open-Domain Question Answering ↩
-
RocketQA: An Optimized Training Approach to Dense Passage Retrieval for Open-Domain Question Answering ↩
-
Unsupervised Corpus Aware Language Model Pre-training for Dense Passage Retrieval ↩
-
HLATR: Enhance Multi-stage Text Retrieval with Hybrid List Aware Transformer Reranking ↩