Design and Implementation of Automated Orchestration Architecture
Architecture of Working Environment
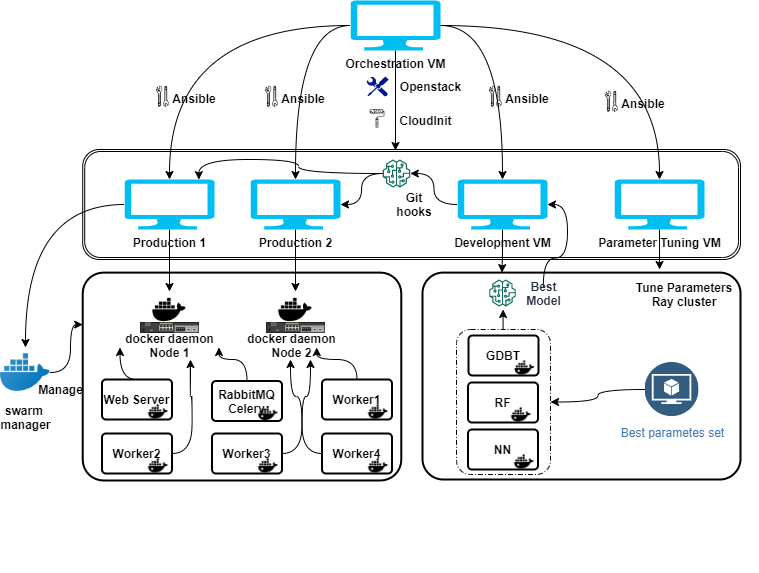 The framework of our project is shown above. We have 5 VMs in total: One VM as the orchestrationVM, development cluster(several containers in the development VM and a Ray cluster consisting of 2 VMs),production cluster(a Docker Swarm cluster consisting of 2 VMs).
The framework of our project is shown above. We have 5 VMs in total: One VM as the orchestrationVM, development cluster(several containers in the development VM and a Ray cluster consisting of 2 VMs),production cluster(a Docker Swarm cluster consisting of 2 VMs).
An important part of our framework is the development cluster(Ray cluster). Since the most time-consumingpart of machine learning model training is the selection, tuning and adjustment of model parameters, we intro-duced the Ray cluster. It consists of two parts, a development server(head node) and several parameter servers.We do the feature extraction and selection, model selection in the development server. After we choose thecandidate models, we will make use of the Ray cluster to do the parameters selection and evaluate them. In this project, docker swarm was used to deploy the services in production VMs, which make the whole systemmore stable and to have a high availability. On the middle right of the figure 1, we deployed development andparameter tuning VMs, we tune the models in Ray Cluster which can speed up the whole process. The bestset of parameters will be used to train different models in different containers, and the best model will push bygit-hooks from development VM to production1 and production2 VMs.
 On the production server, we run multiple containers. The containers guarantee the isolation between tasks.The tasks running in the container include Flask, RabbitMQ and Celery, as well as workers. Flask is a popularPython web service framework. Our web application is developed based in it. In the worker, we predict thegiven data based on the model and get the output. Celery is an asynchronous task queue. It can be used foranything that needs to be run asynchronously. The Broker (RabbitMQ) is responsible for the creation of task2 queues, dispatching tasks to task queues according to some routing rules, and then delivering tasks from taskqueues to workers. The framework of RabbitMQ and Celery is shown above.In our case, we submit a request on a flask-based web application. After receiving the request, the celery clientcalls RabbitMQ to create and assign tasks to workers. After the worker task is completed, the result is storedin the result backend, sent to the web application and displayed.
On the production server, we run multiple containers. The containers guarantee the isolation between tasks.The tasks running in the container include Flask, RabbitMQ and Celery, as well as workers. Flask is a popularPython web service framework. Our web application is developed based in it. In the worker, we predict thegiven data based on the model and get the output. Celery is an asynchronous task queue. It can be used foranything that needs to be run asynchronously. The Broker (RabbitMQ) is responsible for the creation of task2 queues, dispatching tasks to task queues according to some routing rules, and then delivering tasks from taskqueues to workers. The framework of RabbitMQ and Celery is shown above.In our case, we submit a request on a flask-based web application. After receiving the request, the celery clientcalls RabbitMQ to create and assign tasks to workers. After the worker task is completed, the result is storedin the result backend, sent to the web application and displayed.
Tools, Automation and Orchestration
In order to facilitate the reproduction and management of the project, we have automated and orchestrated mostof the steps of the project. Generally speaking, Openstack API is responsible for the automation of creatinginstances on Openstack and configuring their basic environment, Ansible is responsible for managing andmonitoring the VMs, the Ansible playbook is responsible for automatically configuring the detailed operatingenvironment and running programs of each instance, the CI/CD technology(git hook) is used to realize theautomatic push of the latest models to the production server. Most of the configurations including ci/cd areorchestrated by Ansible. Jupyternotebook is used to help to edit the code. Part of the construction of Raycluster and Swarm cluster is also completed automatically by Ansible. But some other settings of the clustersneed to be done manually.
Our development cluster is a Ray cluster. It helps us to speed up the training of our models and parameterstuning. We use Docker Swarm to manage our production cluster. It contains 2 VMs. Docker Swarm providesa set of highly available Docker cluster management solutions, which fully supports the standard Docker API,facilitates the management and scheduling of cluster Docker containers, and makes full use of cluster hostresources. Both the production cluster and the development cluster have scalability in our architecture.
Github
If you want to know more details of our works, please check our reports in Github.