Music classifcation
Problem: music classification
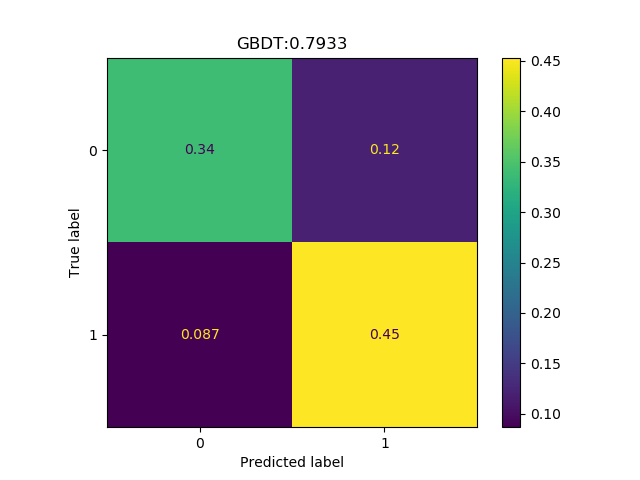
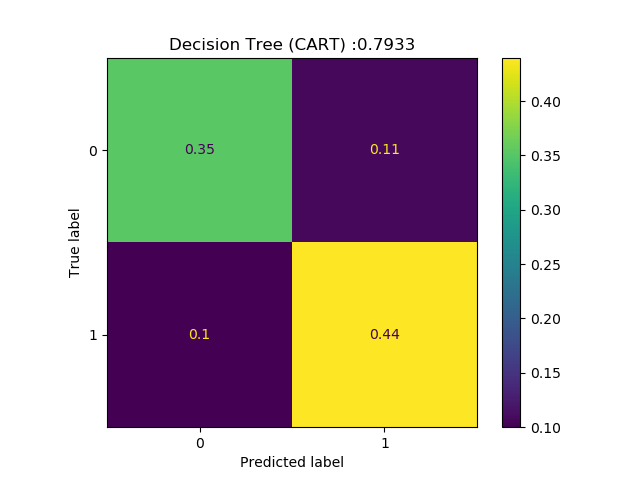
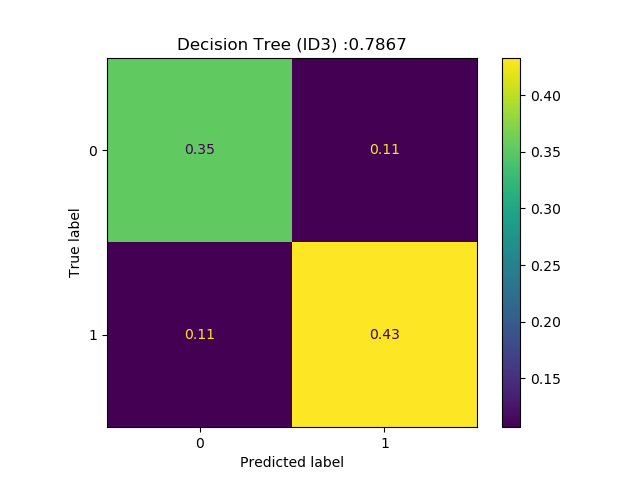
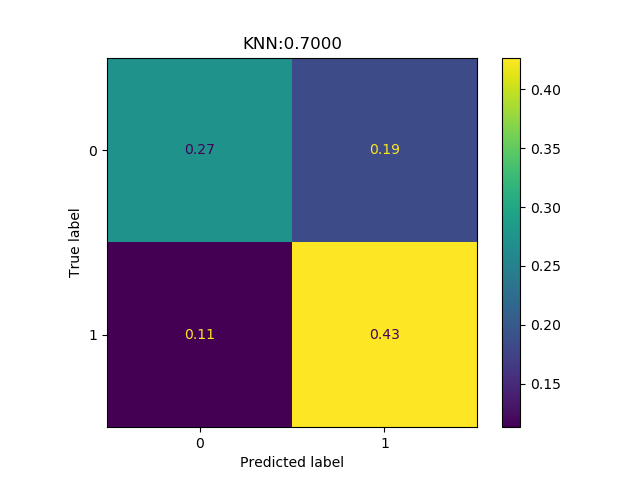
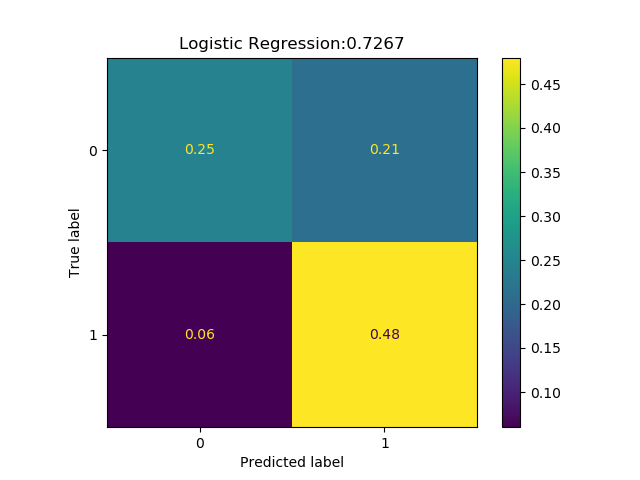
The technical problem is to tell which songs, in a dataset of 200 songs, Andreas Lindholm is going to like (see Figure 1). The data set consists not of the songs themselves, but of high-level features extracted using the web-API from Spotify1. These high-level features describe characteristics such as the acousticness, danceability, energy, instrumentalness, valence and tempo of each song.
To your help, you are provided a training dataset with 750 songs, each of which Andreas has labeled with LIKE or DISLIKE. You are expected to use all the knowledge that you have acquired in the course about classification algorithms, to come up with one algorithm that you think is suited for this problem and which you decide to put ‘in production’.
Dataset
The data set to classify is available as songs_to_classify.csv, and the training data is available as training_data.csv on Studium. The columns in these tables represent extracted features, as specified by the header and documented in Table 1. The column “label” in training_data.csv is encoded as 1 = LIKE and 0 = DISLIKE.
Result